
显存不足怎么办
随着深度学习模型复杂度和数据集规模的增大,计算效率成为了不可忽视的问题。GPU 凭借强大的并行计算能力,成为深度学习加速的标配。然而,由于服务器的显存非常有限,随着训练样本越来越大,显存连一个样本都容不下的现象频频发生。除了升级硬件(烧钱)、使用分布式训练(费力),你知道还有哪些方法吗?即使显存充足,所有运算都在 GPU 上执行就是最高效吗?只要掌握以下小知识,模型训练的种种问题统统搞定,省时省力省钱,重点是高效!

其实 CPU 和 GPU 是协同工作的,如果能合理地利用它们各自的优势,就能够节省显存资源(显存不够内存来凑),甚至获得更好的训练性能。本文为您提供了 device_guard 接口,只需要一行命令,即可实现 GPU 和 CPU 的混合训练,不仅可以解决训练模型时通过调整批尺寸(batch size)显存依ZoRXdYqF然超出的问题,让原本无法在单台服务器执行的模型可以训练,同时本文还给出了提高 GPU //www.czybx.com和 CPU 混合训练效率的方法,将服务器资源利用到极致,帮助您提升模型的性能!
模型训练的特点
深度学习任务通常使用 GPU 进行模型训练。这是因为 GPU 相对于 CPU 具有更多的算术逻辑单元(ALU),可以发挥并行计算的优势,特别适合计算密集型任务,可以更高效地完成深度学习模型的训练。GPU 模式下的模型训练如图1所示,总体可以分为4步:
第1步,将输入数据从系统内存拷贝到显存。
第2步,CPU 指示 GPU 处理数据。
第3步,GPU 并行地完成一系列的计算。
第4步,将计算结果从显存拷贝到内存。
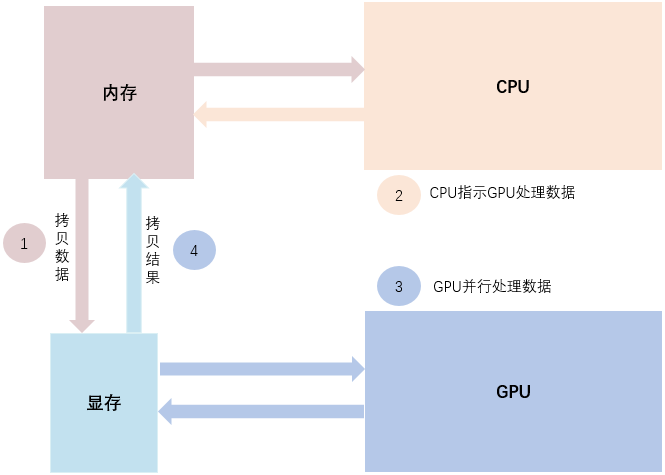
▲ 模型训练示意图
从图中可以了解到,虽然 GPU 并行计算能力优异,但无法单独工作,必须由 CPU 进行控制调用;而且显存和内存之间的频繁数据拷贝也可能会带来较大的性能开销。CPU 虽然计算能力不如 GPU,但可以独立工作,可以直接访问内存数据完成计算。因此,想获得更好的训练性能,需要合理利用 GPU 和 CPU 的优势。
模型训练的常见问题
问题一:GPU 显存爆满,资源不足
你建的模型不错,在这个简洁的任务中可能成为新的 SOTA,但每次尝试批量处理更多样本时,你都会得到一个 CUDA RuntimeError: out of memory。
这是因为 GPU 卡的显存是非常有限的,一般远低于系统内存。以 V100 为例,其显存最高也仅有 32G,甚至有些显存仅 12G 左右。因此当模型的参数量较大时,在 GPU 模式下模型可能无法训练起来。
设置 CPU 模式进行模型训练,可以避免显存不足的问题,但是训练速度往往太慢。
那么有没有一种方法,可以在单机训练中充分地利用 GPU 和 CPU 资源,让部分层在 CPU 执行,部分层在 GPU 执行呢?
问题二:频繁数据拷贝,训练效率低
在显存足够的情况下,我们可以直接采用 GPU 模式去训练模型,但是让所有的网络层都运行在 GPU 上就一定最高效吗?其实 GPU 只对特定任务更快,而 CPU 擅长各种复杂的逻辑运算。框架中有一些 OP 会默认在 CPU 上执行,或者有一些 OP 的输出会被存储在 CPU 上,因为这些输出往往需要在 CPU 上访问。这就会导致训练过程中,CPU 和 GPU 之间存在数据拷贝。
图2是 CPU 和 GPU 数据传输示意图。假设模型的中间层存在下图中的4个算子。其中算子 A 和算子 B 都在 CPU 执行,因此 B 可以直接使用 A 的输出。算子 C 和算子 D 都在 GPU 上执行,那么算子 D 也可以直接使用 C 的输出。但是算子 B 执行完,其输出在 CPU 上,在算子 C 执行时,就会将 B 的输出从 CPU 拷贝到 GPU。
频繁的数据拷贝,也会影响模型的整体性能。如果能把算子 A 和 B 设置在 GPU 上执行,或者算子 C 和 D 设置在 CPU 上执行,避免数据传输,或许会提升模型性能。那么应该如何更加合理地为算子分配设备,使得训练过程更加高效呢?我们需要更综合地考虑,在发挥 GPU 和 CPU 各自计算优势的前提下,降低数据拷贝带来的时间消耗。
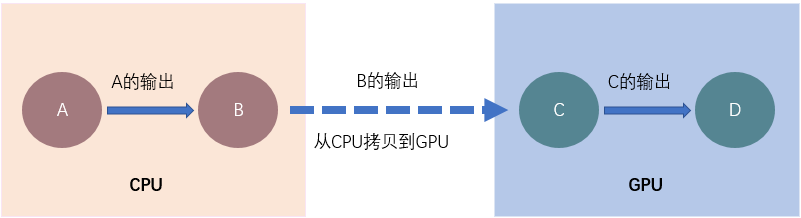
▲ 图2 CPU 和 GPU 数据传输示意图
device_guard 自定义 GPU 和 CPU 混合训练
上面两个场景都是希望为模型中的部分层指定运行设备。飞桨提供了 fluid.CUDAPlace 和 fluid.CPUPlace 用于指定运行设备,但这两个接口在指定设备时是二选一的,也就是说要么在 GPU 模式下训练,要么在 CPU 模式下训练。过去我们无法指定某一部分计算在 GPU 上执行还是在 CPU 上执行。飞桨开源框架从1.8版本开始提供了 device_guard 接口,使用该接口可以为网络中的计算层指定设备为 CPU 或者 GPU,实现更灵活的异构计算调度。
如何使用 device_guard 接口解决上面两个场景中提到的问题呢?接下来,我们看看具体的例子。
好处一:充分利用 CPU 资源,避免显存超出
如果使用 fluid.CUDAPlace 指定了全局的运行设备,飞桨将会自动把支持 GPU 计算的 OP 分配在 GPU 上执行,然而当模型参数量过大并且显存有限时,很可能会遇到显存超出的情况。如下面的示例代码,embedding 层的参数 size 包含两个元素,第一个元素为 vocab_size(词表大小),第二个为 emb_size(embedding 层维度)。实际场景中,词表可能会非常大。示例代码中,词表大小被设置为10,000,000,该层创建的权重矩阵的大小为(10000000, 150),仅这一层就需要占用 5.59G 的显存。如果再加上其他的网络层,在这种大词表场景下,很有可能会显存超出。
importpaddle.fluid asfluid
data = fluid.layers.fill_constant(shape=[ 1], value= 128, dtype= 'int64')
label = fluid.layers.fill_constant(shape=[ 1, 150], value= 0.5, dtype= 'float32')
emb = fluid.embedding(input=data, size=( 10000000, 150), dtype= 'float32')
out = fluid.layers.l2_normalize(x=emb, axis= -1)
cost = fluid.layers.square_error_cost(input=out, label=label)
avg_cost = fluid.layers.mean(cost)
sgd_optimizer = fluid.optimizer.SGD(learning_rate= 0.001)
sgd_optimizer.minimize(avg_cost)
place = fluid.CUDAPlace( 0)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program)
result = exe.run(fluid.default_main_program, fetch_list=[avg_cost])
embedding 是根据 input 中的 id 信息从 embedding 矩阵中查询对应 embedding 信息,它并不是一个计算密度非常高的 OP,因此在 CPU 上进行计算,其速度也是可接受的。如果将 embedding 层设置在 CPU 上运行,就能够充分利用 CPU 大内存的优势,避免显存超出。可以参考如下代码,使用 device_guard 将 embedding 层设置在 CPU 上。那么,除了 embedding 层,其他各层都会在 GPU 上运行。
importpaddle.fluid asfluid
data = fluid.layers.fill_constant(shape=[ 1], value= 128, dtype= 'int64')
label = fluid.layers.fill_constant(shape=[ 1, 150], value= 0.5, dtype= 'float32')
withfluid.device_guard( "cpu"): #一行命令,指定该网络层运行设备为CPU
emb = fluid.embedding(input=data, size=( 10000000, 150), dtype= 'float32')
out = fluid.layers.l2_normalize(x=emb, axis= -1)
cost = fluid.layers.square_error_cost(input=out, label=label)
avg_cost = fluid.layers.mean(cost)
sgd_optimizer = fluid.optimizer.SGD(learning_rate= 0.001)
sgd_optimizer.minimize(avg_cost)
place = fluid.CUDAPlace( 0)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program)
result = exe.run(fluid.default_main_program, fetch_list=[avg_cost])
因此,在显存有限时你可以参考上面的示例将一些计算密度不高的网络层设置在 CPU 上避免显存超出。
好处二:合理设置运行设备,减少数据传输
如果你在 GPU 模式下训练模型,希望提升训练速度,那么可以看看模型中是否存在一些不必要的数据传输。在文章开头我们提到 CPU 和 GPU 之间的数据拷贝是耗时的,因此如果能够避免这样的情况,就有可能提升模型的性能。
在下面的内容中,我们将教你如何通过 profile 工具分析数据传输开销,以及如何使用 device_guard 避免不必要的数据传输,从而提升模型性能。大致流程如下:
- 首先使用 profile 工具对模型进行分析,查看是否存在 GpuMemcpySync 的调用耗时。若存在,则进一步分析发生数据传输的原因。
- 通过 Profiling Report 找到发生 GpuMemcpySync 的 OP。如果需要,可以通过打印 log,找到 GpuMemcpySync 发生的具体位置。
- 尝试使用 device_guard 设置部分 OP 的运行设备,来减少 GpuMemcpySync 的调用。
- 最后比较修改前后模型的 Profiling Report,或者其他用来衡量性能的指标,确认修改后是否带来了性能提升。
步骤1 使用 profile 工具确认是否发生了数据传输
首先我们需要分析模型中是否存在 CPU 和 GPU 之间的数据传输。在 OP 执行过程中,如果输入 Tensor 所在的设备与 OP 执行的设备不同,就会自动将输入 Tensor 从 CPU 拷贝到 GPU,或者从 GPU 拷贝到 CPU,这个过程是同步的数据拷贝,通常比较耗时。下列示例代码的14行设置了 profile,利用 profile 工具我们可以看到模型的性能数据。
importpaddle.fluid asfluid
importpaddle.fluid.compiler ascompiler
importpaddle.fluid.profiler asprofiler
data1 = fluid.layers.fill_constant(shape=[ 1, 3, 8, 8], value= 0.5, dtype= 'float32')
data2 = fluid.layers.fill_constant(shape=[ 1, 3, 5, 5], value= 0.5, dtype= 'float32')
shape = fluid.layers.shape(data2)
shape = fluid.layers.slice(shape, axes=[ 0], starts=[ 0], ends=[ 4])
out = fluid.layers.crop_tensor(data1, shape=shape)
place = fluid.CUDAPlace( 0)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program)
compiled_prog = compiler.CompiledProgram(fluid.default_main_program)
withprofiler.profiler( 'All', 'total') asprof:
fori inrange( 10):
result = exe.run(program=compiled_prog, fetch_list=[out])
在上述程序运行结束后,将会自动地打印出下面的 Profiling Report,可以看到 GpuMemCpy Summary 中给出了2项数据传输的调用耗时。如果 GpuMemCpy Summary 中存在 GpuMemcpySync,那么就说明你的模型中存在同步的数据拷贝。
进一步分析,可以看到 slice 和 crop_tensor 执行中都发生了 GpuMemcpySync。我们通过查看网络的定义,就会发现尽管我们在程序中设置了 GPU 模式运行,但是 shape 这个 OP 将输出结果存放在 CPU 上,导致后面在 GPU 上执行的 slice 使用这个结果时发生了从 CPU 到 GPU 的数据拷贝。slice 的输出结果存放在 GPU上,而 crop_tensor 用到这个结果的参数默认是从 CPU 上取数据,因此又发生了一次数据拷贝。
-------------------------> Profiling Report <-------------------------
Note! This Report merge all thread info into one.
Place: All
Time unit: ms
Sorted by total time indescending order inthe same thread
Total time: 26.6328
Computation time Total: 13.3133Ratio: 49.9884%
Framework overhead Total: 13.3195Ratio: 50.0116%
------------------------- GpuMemCpy Summary -------------------------
GpuMemcpy Calls: 30Total: 1.47508Ratio: 5.5386%
GpuMemcpyAsync Calls: 10Total: 0.443514Ratio: 1.66529%
GpuMemcpySync Calls: 20Total: 1.03157Ratio: 3.87331%
------------------------- Event Summary -------------------------
Event Calls Total CPU Time (Ratio) GPU Time (Ratio) Min. Max. Ave. Ratio.
FastThreadedSSAGraphExecutorPrepare 109.164939.152509( 0.998645) 0.012417( 0.001355) 0.0251928.859680.9164930.344122
shape 108.330578.330568( 1.000000) 0.000000( 0.000000) 0.0307117.998490.8330570.312793
fill_constant 204.060974.024522( 0.991025) 0.036449( 0.008975) 0.0750870.8889590.2030490.15248
slice 101.780331.750439( 0.983212) 0.029888( 0.016788) 0.1485030.2908510.1780330.0668471
GpuMemcpySync:CPU->GPU 100.455240.446312( 0.980388) 0.008928( 0.019612) 0.0390890.0606940.0455240.0170932
crop_tensor 101.676581.620542( 0.966578) 0.056034( 0.033422) 0.1439060.2587760.1676580.0629515
GpuMemcpySync:GPU->CPU 100.576330.552906( 0.959357) 0.023424( 0.040643) 0.0506570.0763220.0576330.0216398
Fetch 100.9193610.895201( 0.973721) 0.024160( 0.026279) 0.0829350.1381220.09193610.0345199
GpuMemcpyAsync:GPU->CPU 100.4435140.419354( 0.945526) 0.024160( 0.054474) 0.0406390.0596730.04435140.0166529
ScopeBufferedMonitor::post_local_exec_scopes_process 100.3419990.341999( 1.000000) 0.000000( 0.000000) 0.0284360.0571340.03419990.0128413
eager_deletion 300.2872360.287236( 1.000000) 0.000000( 0.000000) 0.0054520.0226960.009574530.010785
ScopeBufferedMonitor::pre_local_exec_scopes_process 100.0478640.047864( 1.000000) 0.000000( 0.000000) 0.0036680.0115920.00478640.00179718
InitLocalVars 10.0229810.022981( 1.000000) 0.000000( 0.000000) 0.0229810.0229810.0229810.000862883
步骤2 通过 log 查看发生数据传输的具体位置
有时同一个 OP 会在模型中被用到很多次,例如可能我们会在网络的几个不同位置,都定义了 slice 层。这时候想要确认究竟是在哪个位置发生了数据传输,就需要去查看更加详细的调试信息,那么可以打印出运行时的 log。依然以上述程序为例,执行 GLOG_vmodule=operator=3 python test_case.py,会得到如下 log 信息,可以看到这两次数据传输:
- 第3~7行 log 显示:shape 输出的结果在 CPU 上,在 slice 运行时,shape 的输出被拷贝到 GPU 上;
- 第9~10行 log 显示:slice 执行完的结果在 GPU 上,当 crop_tensor 执行时,它会被拷贝到 CPU 上。
I0406 14: 56: 23.28659217516operator.cc: 180] CUDAPlace( 0) Op(shape), inputs:{Input[fill_constant_1.tmp_0:float[ 1, 3, 5, 5]({})]}, outputs:{Out[shape_0.tmp_0:int[ 4]({})]}.
I0406 14: 56: 23.28662817516eager_deletion_op_handle.cc: 107] Erase variable fill_constant_1.tmp_0 on CUDAPlace( 0)
I0406 14: 56: 23.28672517516operator.cc: 1210] Transform Variable shape_0.tmp_0 fromdata_type[int]:data_layout[NCHW]:place[CPUPlace]:library_type[PLAIN] to data_type[int]:data_layout[ANY_LAYOUT]:place[CUDAPlace( 0)]:library_type[PLAIN]
I0406 14: 56: 23.28676317516scope.cc: 169] Create variable shape_0.tmp_0
I0406 14: 56: 23.28678417516data_device_transform.cc: 21] DeviceTransform in, src_place CPUPlace dst_place: CUDAPlace( 0)
I0406 14: 56: 23.28686717516tensor_util.cu: 129] TensorCopySync 4fromCPUPlace to CUDAPlace( 0)
I0406 14: 56: 23.28709917516operator.cc: 180] CUDAPlace( 0) Op(slice), inputs:{EndsTensor[], EndsTensorList[], Input[shape_0.tmp_0:int[ 4]({})], StartsTensor[], StartsTensorList[]}, outputs:{Out[slice_0.tmp_0:int[ 4]({})]}.
I0406 14: 56: 23.28714017516eager_deletion_op_handle.cc: 107] Erase variable shape_0.tmp_0 on CUDAPlace( 0)
I0406 14: 56: 23.28722017516tensor_util.cu: 129] TensorCopySync 4fromCUDAPlace( 0) to CPUPlace
I0406 14: 56: 23.28747317516operator.cc: 180] CUDAPlace( 0) Op(crop_tensor), inputs:{Offsets[], OffsetsTensor[], Shape[slice_0.tmp_0:int[ 4]({})], ShapeTensor[], X[fill_constant_0.tmp_0:float[ 1, 3, 8, 8]({})]}, outputs:{Out[crop_tensor_0.tmp_0:float[ 1, 3, 5, 5]({})]}.
步骤3 使用 device_guard 避免不必要的数据传输
在上面的例子中,shape 输出的是一个 1-D 的 Tensor,因此在 slice 执行时,计算代价相对于数据传输代价或许是更小的。如果将 slice 设置在 CPU 上运行,就可以避免2次数据传输,那么是不是有可能提升模型速度呢?我们尝试修改程序,将 slice 层设置在 CPU 上执行:
importpaddle.fluid asfluid
importpaddle.fluid.compiler ascompiler
importpaddle.fluid.profiler asprofiler
data1 = fluid.layers.fill_constant(shape=[ 1, 3, 8, 8], value= 0.5, dtype= 'float32')
data2 = fluid.layers.fill_constant(shape=[ 1, 3, 5, 5], value= 0.5, dtype= 'float32')
shape = fluid.layers.shape(data2)
withfluid.device_guard( "cpu"): # 一行命令,指定该网络层运行设备为CPU
shape = fluid.layers.sli白熊资讯网ce(shape, axes=[ 0], starts=[ 0], ends=[ 4])
out = fluid.layers.crop_tensor(data1, shape=shape)
place = fluid.CUDAPlace( 0)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program)
compiled_prog = compiler.CompiledProgram(fluid.default_main_program)
withprofiler.profiler( 'All', 'total') asprof:
fori inrange( 10):
result = exe.run(program=compiled_prog, fetch_list=[out])
步骤4 比较修改前后模型,确认是否带来性能提升
再次观察 Profiling Report 中 GpuMemCpy Summary 的内容,可以看到 GpuMemCpySync 这一项已经被消除了。同时注意到,下面的 Total time 为 14.5345ms,而修改前是 26.6328ms,速度提升一倍!此实验说明使用 device_guard 避免数据传输后,示例模型的性能有了明显的提升。
在实际的模型中,若 GpuMemCpySync 调用耗时占比较大,并且可以通过设置 device_guard 避免,那么就能够带来一定的性能提升。
-------------------------> Profiling Report <-------------------------
Note! This Report merge all thread info into one.
Place: All
Time unit: ms
Sorted by total time indescending order inthe same thread
Total time: 14.5345
Computation time Total: 4.47587Ratio: 30.7948%
Framework overhead Total: 10.0586Ratio: 69.2052%
------------------------- GpuMemCpy Summary -------------------------
GpuMemcpy Calls: 10Total: 0.457033Ratio: 3.14447%
GpuMemcpyAsync Calls: 10Total: 0.457033Ratio: 3.14447%
------------------------- Event Summary -------------------------
Event Calls Total CPU Time (Ratio) GPU Time (Ratio) Min. Max. Ave. Ratio.
FastThreadedSSAGraphExecutorPrepare 107.701137.689066( 0.998433) 0.012064( 0.001567) 0.0326577.393630.7701130.529852
fill_constant 202.622992.587022( 0.986287) 0.035968( 0.013713) 0.0710970.3420820.131150.180466
shape 101.935041.935040( 1.000000) 0.000000( 0.000000) 0.0267741.601ZoRXdYqF60.1935040.133134
Fetch 100.8804960.858512( 0.975032) 0.021984( 0.024968) 0.073920.1408960.08804960.0605797
GpuMemcpyAsync:GPU->CPU 100.4570330.435049( 0.951898) 0.021984( 0.048102) 0.0378360.0714240.04570330.0314447
crop_tensor 100.7054260.671506( 0.951916) 0.033920( 0.048084) 0.058410.1239010.07054260.0485346
slice 100.3242410.324241( 1.000000) 0.000000( 0.000000) 0.0242990.072130.03242410.0223084
eager_deletion 300.2505240.250524( 1.000000) 0.000000( 0.000000) 0.0041710.0162350.00835080.0172365
ScopeBufferedMonitor::post_local_exec_scopes_process 100.0477940.047794( 1.000000) 0.000000( 0.000000) 0.0033440.0141310.00477940.00328831
InitLocalVars 10.0346290.034629( 1.000000) 0.000000( 0.000000) 0.0346290.0346290.0346290.00238254
ScopeBufferedMonitor::pre_local_exec_scopes_process 100.0322310.032231( 1.000000) 0.000000( 0.000000) 0.0029520.0040760.00322310.00221755
总 结
通过以上实验对比可以发现,deviZoRXdYqFce_guard 接口能够做到一条命令即可合理设置模型网络层的运行设备,对模型进行 GPU 和 CPU 计算的更灵活调度,将服务器的资源利用到极致,解决显存容量捉襟见肘导致模型无法训练的问题。怎么样,这个功能是不是相当实用!心动不如心动,快快参考本文的方法,尽情训练自己的模型吧!
如在使用过程中有问题,可加入飞桨官方 QQ 群交流:1108045677
官网地址:
https://www.paddlepaddle.org.cn
飞桨开源框架项目地址:
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle
内容版权声明:除非注明原创否则皆为转载,再次转载请注明出处。
文章标题: 显存不足怎么办